
From multiple usages of Large Language Models, all of us have seen the disclaimers that say they can make mistakes.
Accuracy in models like ChatGPT isn’t a fixed value either, it is known to change with user interactions and model updates.
Let’s dig further to determine how accurate the various GPT models can be by looking at multiple studies done on this topic.
On this page
- Key ChatGPT Accuracy Statistics
- OpenAI-o1-Mini Has Second Lowest Hallucination Rate in Top 25 LLMs
- ChatGPT Versus Other Models
- ChatGPT’s Accuracy in Medicine
- OpenAI o1 Scored 83% on an IMO Qualifying Exam, Compared to 13% by GPT-4o
- ChatGPT's Accuracy Can Fall Over Time
- ChatGPT's Accuracy Can Also Improve Over Time in Some Cases
- Statistics on ChatGPT’s Performance in Scholastic Exams
- Open AI Shut Down Its AI Classifier Within Six Months of Launch Due to Low Accuracy Rate
- Final Thoughts on The Future of LLMs
Key ChatGPT Accuracy Statistics
1. OpenAI o1 scored 83% on an IMO qualifying exam.
2. In creating images for medical research papers, ChatGPT-4 performed poorly.
3. O1 performs at the same level as PhD students on various physics, chemistry, and biology benchmarks.
4. OpenAI-o1-Mini has one of the lower hallucination rates at 1.4%.
5. ChatGPT was 77% accurate in making the final diagnosis for patients.
OpenAI-o1-Mini Has Second Lowest Hallucination Rate in Top 25 LLMs
According to a GitHub post, where Vectera evaluated many large language models concerning their hallucination rate, OpenAI-o1-Mini came second.
It was found to have a hallucination rate of 1.4%.
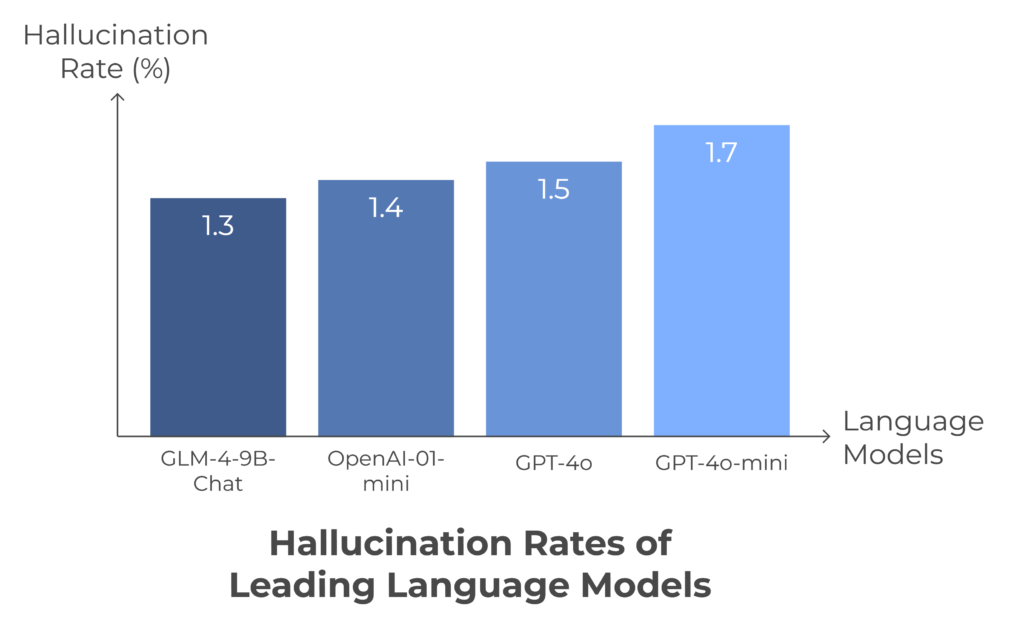
In that same December 2024 snapshot, GLM-4-9B-Chat sat just ahead at a 1.3% hallucination rate. The leaderboard has since been rebuilt on a harder dataset, so the leaders and rates have shifted.
ChatGPT’s “False Citation Rates” Across Various Psychology Subfields Range From 6%-60%
The fake citations used legitimate researchers’ names and credentials, giving a false sense of legitimacy and confusing students/researchers. (Canadian Psychological Association, 2023)
Aritificial intelligence hence can’t be trusted, and it is better to rely on expert human feedback when it comes to serious matters.
ChatGPT Versus Other Models
How does ChatGPT, or the latest model GPT-4o, compare with other models like Anthropic’s Claude or Google’s Gemini?
It turns out that GPT-4o stands out in a league of its own when compared with its previous iterations of ai models.
GPT-4o Stands Out for Its Remarkable Performance Across a Broad Range of Languages
The languages where the LLMs- GPT-4o, Gemini 1.5, and Claude Opus were tested were Spanish, German, French, Portuguese, and Russian, as well as more niche languages.
Here is the list of languages, with their abbreviations:
Here’s the list extracted from the image:
| Language Code | Language |
|---|---|
| de | German |
| en | English |
| es | Spanish |
| fi | Finnish |
| fr | French |
| no | Norwegian |
| pt | Portuguese |
| ru | Russian |
| sv | Swedish |
| nl | Dutch |
GPT-4o outshines its previous models- GPT-4 and GPT-4 turbo. (Archive, 2024)
Claude 3.5 Sonnet (72%) Outperforms GPT-4o (65%) in Mean Accuracy
These models were compared to each other on tasks like data extraction, ticket classification, and verbal reasoning. (Vellum, 2024)
GPT-4o Has a Small Lead in Precision (86.21%), Compared to Claude 3.5 Sonnet (85%)
In model comparison tests done by Vellum, GPT-4o had a small lead in precision at 86.21%, compared to Claude 3.5 Sonnet (85%). (Vellum, 2024)
Here’s a table comparing the performance of Claude 3.5 Sonnet, Claude 3 Opus, and GPT-4o across the listed categories:
| Category | Claude 3.5 Sonnet | Claude 3 Opus | GPT-4o |
|---|---|---|---|
| Graduate level reasoning (GPAQ, Diamond) | 59.4% (0-shot CoT) | 50.4% (0-shot CoT) | 53.6% (0-shot CoT) |
| Undergraduate level knowledge (MMLU) | 88.7% (5-shot), 88.3% (0-shot CoT) | 86.8% (5-shot), 85.7% (0-shot CoT) | 88.7% (0-shot CoT) |
| Code (HumanEval) | 92.0% (0-shot) | 84.9% (0-shot) | 90.2% (0-shot) |
| Multilingual math (MGSM) | 91.6% (0-shot CoT) | 90.7% (0-shot CoT) | 90.5% (0-shot CoT) |
| Reasoning over text (DROP, F1 score) | 87.1% (3-shot) | 83.1% (3-shot) | 83.4% (3-shot) |
| Mixed evaluations (BIG-Bench-Hard) | 93.1% (3-shot CoT) | 86.8% (3-shot CoT) | — |
| Math problem-solving (MATH) | 71.1% (0-shot CoT) | 60.1% (0-shot CoT) | 76.6% (0-shot CoT) |
| Grade school math (GSM8K) | 96.4% (0-shot CoT) | 95.0% (0-shot CoT) | — |
Let me know if you need further modifications!
ChatGPT’s Accuracy in Medicine
There has been a lot of buzz about AI being used in healthcare, especially since there is a healthcare crisis where many regions face staffing shortages.
Although ChatGPT can’t replace actual doctors, many people have been consulting it for clinical situations.
Let’s look at some of the stats on this.
The Median Accuracy Score of ChatGPT in Medical Tests Was 5.5
This translates to almost or completely correct in terms of accuracy. (NCBI, 2023)
ChatGPT Was 77% Accurate in Making the Final Diagnosis
The author of the paper said that ChatGPT was comparable to the level of medical students just graduating from medical school.
It performed more poorly in making differential diagnosis, with an accuracy of only 60 percent. (JMIR, 2023)
GPT-4 Solves All Common Cases Within Two Suggested Diagnoses

Despite the good diagnostic accuracy, the authors of the paper claim that it can be used as a tool for doctors, but non-doctors should use it carefully. (medRxiv, 2023)
For Rare Disease Conditions, ChatGPT-4 Needed Eight or More Suggestions
It was only after 8 or more suggestions that it got an accuracy of 90%, for rare diseases.
This shows that suggestions (more data) can help ChatGPT give a more accurate diagnosis.
Yet the number of suggestions is still on the larger side, with 8 or more. (Research Gate, 2023)
Yet, ChatGPT can’t be blindly used in clinical decision making yet, as in another study ChatGPT had an 83% error rate.
ChatGPT Version 4 Rendered a Correct Final Diagnosis in 39% of (NEJM) Case Challenges
NEJM stands for New England Journal of Medicine.
Apart from answering medical questions, ChatGPT could also make admin work more efficient.
ChatGPT responses could even help in writing research articles or coming up with instruction sheets for patient aftercare. (JAMA Network, 2023)
ChatGPT-4 Demonstrated a 76.4% Accuracy Rate on the Korean General Surgery Board Exam
This was significantly higher than GPT-3.5’s 46.8%.
The testdataset contained 280 questions taken from the Korean General Surgery Board exams, which were administered during 2020-2022.
Across subspecialties, GPT-4 showed accuracy rates ranging from 63%-83%. (ASTR, 2023)
OpenAI o1 Scored 83% on an IMO Qualifying Exam, Compared to 13% by GPT-4o
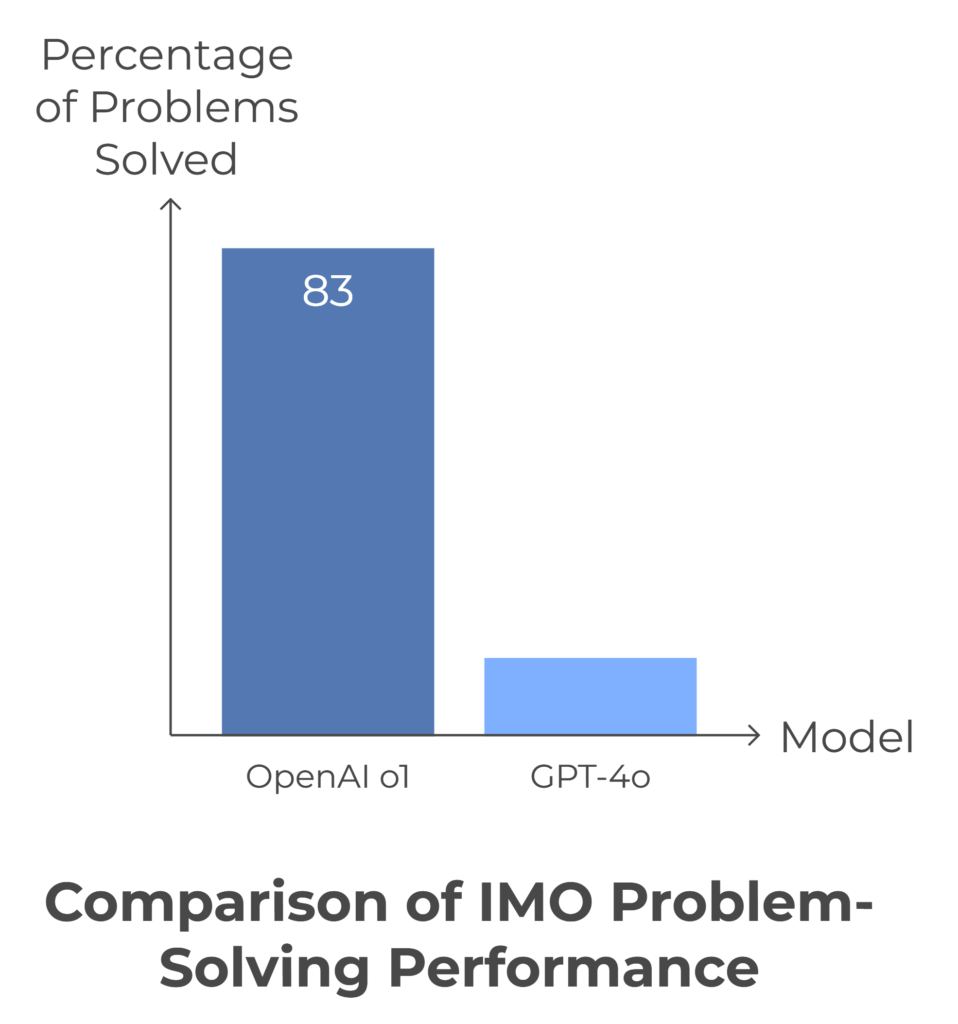
This corresponds to the top 500 students in the US for math olympiads.
OpenAI’s o1 has recently been released and is already breaking records in quite a few LLM evals.
Let’s look at some of the main ones.
It Performs at the Same Level as PhD Students on Various Benchmarks in Physics, Chemistry, and Biology
According to OpenAI, this represents a statistically significant difference in improvement in AI capabilities, which is why they’ve restarted the level at 1 in their model name-OpenAI o1.
OpenAI’s o1 Reached the 89th Percentile in Codeforces Competitions
Codeforces is a platform that is used to practice for competitive coding tests, it also hosts its own contests and has 2+ million users.
The New Model Also Scored 84/100 in Important Jailbreaking Tests
Jailbreaking is basically a way to bypass the limitations that are set on LLMS, which can render them prone to manipulation.
On OpenAI’s hardest jailbreaking test, the previous model GPT-4o scored 22, while o1 scored 84.
Open AI says it will make its AI model o1-mini accessible to all ChatGPT Free users in the future.
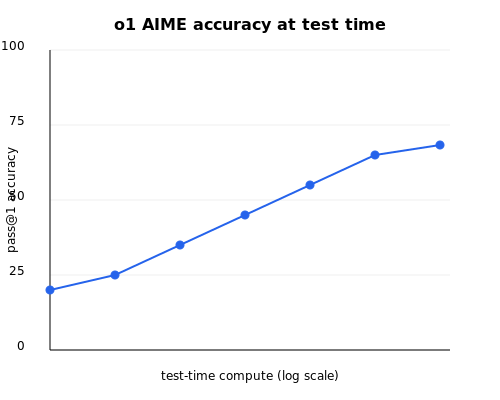
The model’s history hasn’t been very rosy though, with some of their previous models losing their accuracy over time.
Here is the test-time accuracy graph for o1, note that the time-axis is a log scale.
ChatGPT’s Accuracy Can Fall Over Time
According to an Arxiv paper, the LLm drift is due to changes in ChatGPT’s
ability to follow user instructions.
GPT-4, in March 2023, was very good at following user instructions, but in June, it failed to follow even simple instructions.
Hence even after a model is released, it is important to monitor its usability over time, and until now this issue hasn’t been properly solved.
GPT-4’s Accuracy Dropped from 84.0% in March to 51.1% in June 2023
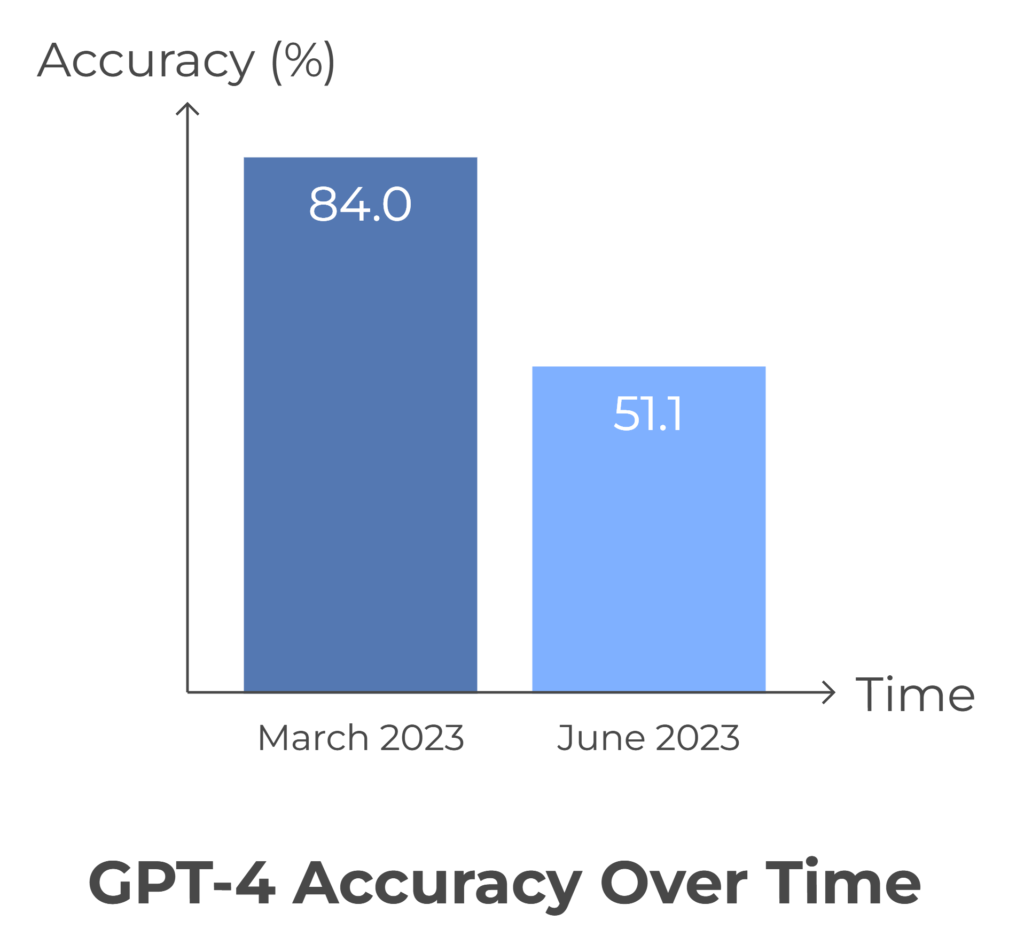
GPT-4 couldn’t follow Chain-of-Thought prompting anymore, which partially explains the accuracy drop.
In Creating Images for Medical Research Papers, ChatGPT-4 Performed Poorly
All the images were rated below average and couldn’t be used in the papers yet. (PubMed, 2024)
A user on the OpenAI Forum reported that GPT-4’s accuracy rate is much lower with image queries, at around 50%.
ChatGPT’s Accuracy Can Also Improve Over Time in Some Cases
LLM drift isn’t always negative, there can be positive changes in accuracy too.
ChatGPT-4o Is 99% Accurate in English
Claude-3 Opus outperforms it though, and scores an almost 100% accuracy in Swedish. (Archive, 2024)
Statistics on ChatGPT’s Performance in Scholastic Exams
Let’s see how ChatGPT performs on famous Scholastic exams such as the SAT and the USMLE.
ChatGPT’s performance on the USMLE Exams Showed accuracy rates ranging from 42% to 64.4%
USMLE stands for US Medical Licensing Examination.
The accuracy had a notable decrease in performance as question difficulty increased. (JMIR, 2023)
How does the GPT-4o model compare?
Let’s look at an Arxiv paper that explores GPT-4o’s accuracy on various scholastic metrics.
The Model Scores 90% Accuracy on USMLE
The USMLE is a three-step test series that medical graduates must pass to practice medicine in the U.S. It evaluates medical knowledge, principles, and patient-centered skills.
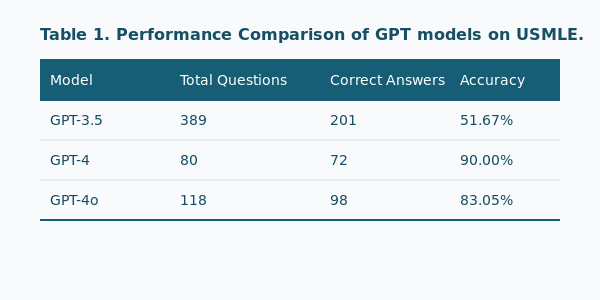
Here, GPT-4 dominates with an accuracy of 90.00% on USMLE, with GPT-4o at 83.05% follows.
GPT-4o Scores Around the 90th Percentile on the SAT
The SAT is the most important entrance exam used by most colleges and universities to make admissions decisions in the US.
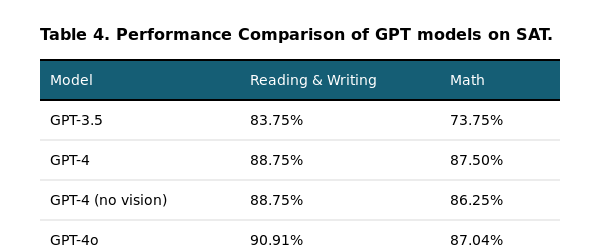
GPT-4o is the best-performing model on the SAT with an accuracy 90.1% in Reading and Writing, while GPT-4 is the best in the Math Section with 87.50%.
GPT-4o Is Around 85% Accurate for the CFA Level 1 Exam
The CFA Program is a three-part exam that tests the fundamentals of investment tools, valuing assets, portfolio management, and wealth planning.
The CFA Program is typically completed by those with backgrounds in finance, accounting, economics, or business.

GPT-4o has the highest accuracy of 85.39% on the CFA level 1 Exam, followed by GPT-4 at 73.2% and GPT 3.5 at a much lower 58.8%.
Open AI Shut Down Its AI Classifier Within Six Months of Launch Due to Low Accuracy Rate
The classifier had a true positive rate of only 26%, where the reliability of the output to be correctly identified increased with input length. (OpenAI, 2023)
This shows that even AI detectors made from frontier companies like OpenAI, which themselves create AI generators, find it difficult to distinguish human versus AI written content.
OpenAI Claimed to Have an Internal Tool That Can Detect AI-generated Images With 99% Accuracy
Mira Murati, CTO of OpenAI, mentioned that OpenAI’s tool is 99% reliable for detecting AI images. (Business Standard, 2023)
Final Thoughts on The Future of LLMs
Here are some quick tips from Aidbase AI on how you can improve get more accurate responses from your large language model:
- Be specific with prompts and guidelines, giving a few examples to learn from is also great.
- Add context and background information, which would help set the perspective required for the scenario.
- You can use chain-of-thought prompting, which goes through the reasoning step by step for more complex questions.
About the author
Editorial Staff
The Editorial Staff at Bot Memo is a team of writers, analysts, and AI agents dedicated to mapping the global AI startup ecosystem. Led by Chintan Zalani, the team tracks thousands of funding rounds, classifies companies across verticals, and distills it all into actionable intelligence for investors and founders.

